Using Language Models to make sense of Chat Data without compromising user privacy
If you're interested in the code for this article, you can find it here where I've implemented a simplified version of CLIO without the PII classifier and most of the original prompts ( to some degree ).
Analysing chat data at scale is a challenging task for 3 main reasons
- Privacy - Users don't want their data to be shared with others and we need to respect that. This makes it challenging to do analysis on user data that's specific
- Explainability - Unsupervised clustering methods are sometimes difficult to interpret because we don't have a good way to understand what the clusters mean.
- Scale - We need to be able to process large amounts of data efficiently.
An ideal solution allows us to understand broad general trends and patterns in user behaviour while preserving user privacy. In this article, we'll explore an approach that addresses this challenge - Claude Language Insights and Observability ( CLIO ) which was recently discussed in a research paper released by Anthropic.
We'll do so in 3 steps
- We'll start by understanding on a high level how CLIO works
- We'll then implement a simplified version of CLIO in Python
- We'll then discuss some of the clusters that we generated and some of the limitations of such an approach
Let's walk through these concepts in detail.
CLIO
High Level Overview
You can read about CLIO in Anthropic's blog post here. Personally I just asked Claude to explain it to me and it did a good job.
On a high level, it uses two main techniques to understand user conversations at scale
- Clustering - Anthropic uses a K-Means clustering algorithm to group similar conversations/clusters together using their embeddings. The exact hyper-parameter of
kwasn't disclosed in their paper but they mention it's a function of the dataset they use. - LLMs Labels - Given a set of clusters or conversation summaries, they use a combination of
claude-3.5-haikuandclaude-3-opusto generate new potential clusters that combine these child clusters and recursively apply this process until we have a number of clusters that we want.
We can see this from the diagram below where we have initial private user conversations that get increasingly summarised and clustered so that the broad general trends are preserved while omitting the specific user details.
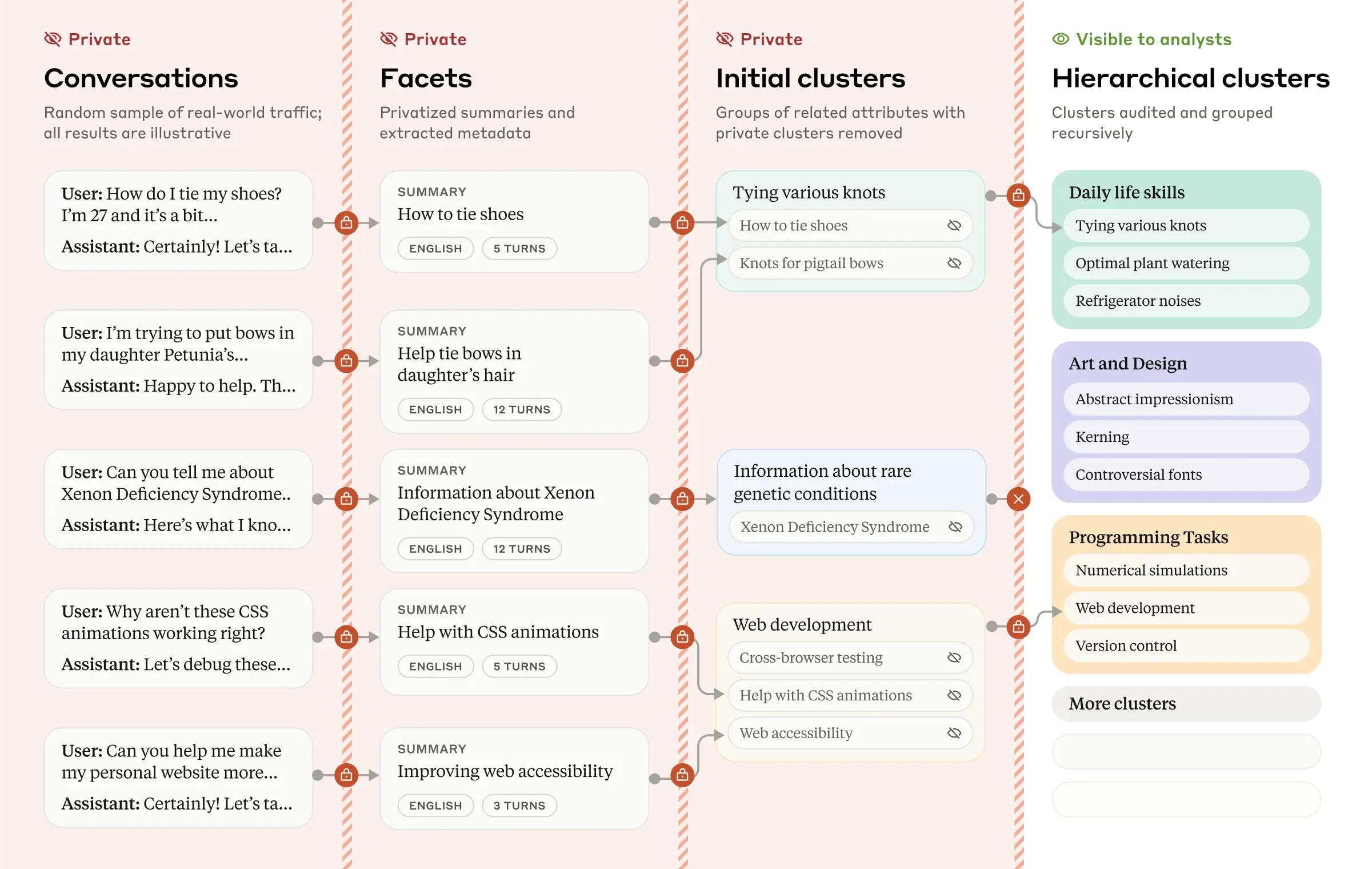
This in turn creates overall patterns that can be used to understand user behaviour as seen below
What's interesting about this
I think there are three interesting things about this approach that really stood out to me from the original paper
Synthetic Data
CLIO was validated by using a largely synthetic dataset that was generated by Claude. This comprised approximately ~20k conversations that spanned across 15 different languages and 18 high level topics.

The final clusters were then manually validated by Anthropic's team to ensure that they were meaningful. This is interesting because they then used it as a way to systematically probe specific weaknesses that Claude has for specific models.
PII Classifier
Anthropic also used a PII classifier to ensure that conversations were anonymised. Their definition of PII was interesting and I'll quote it here
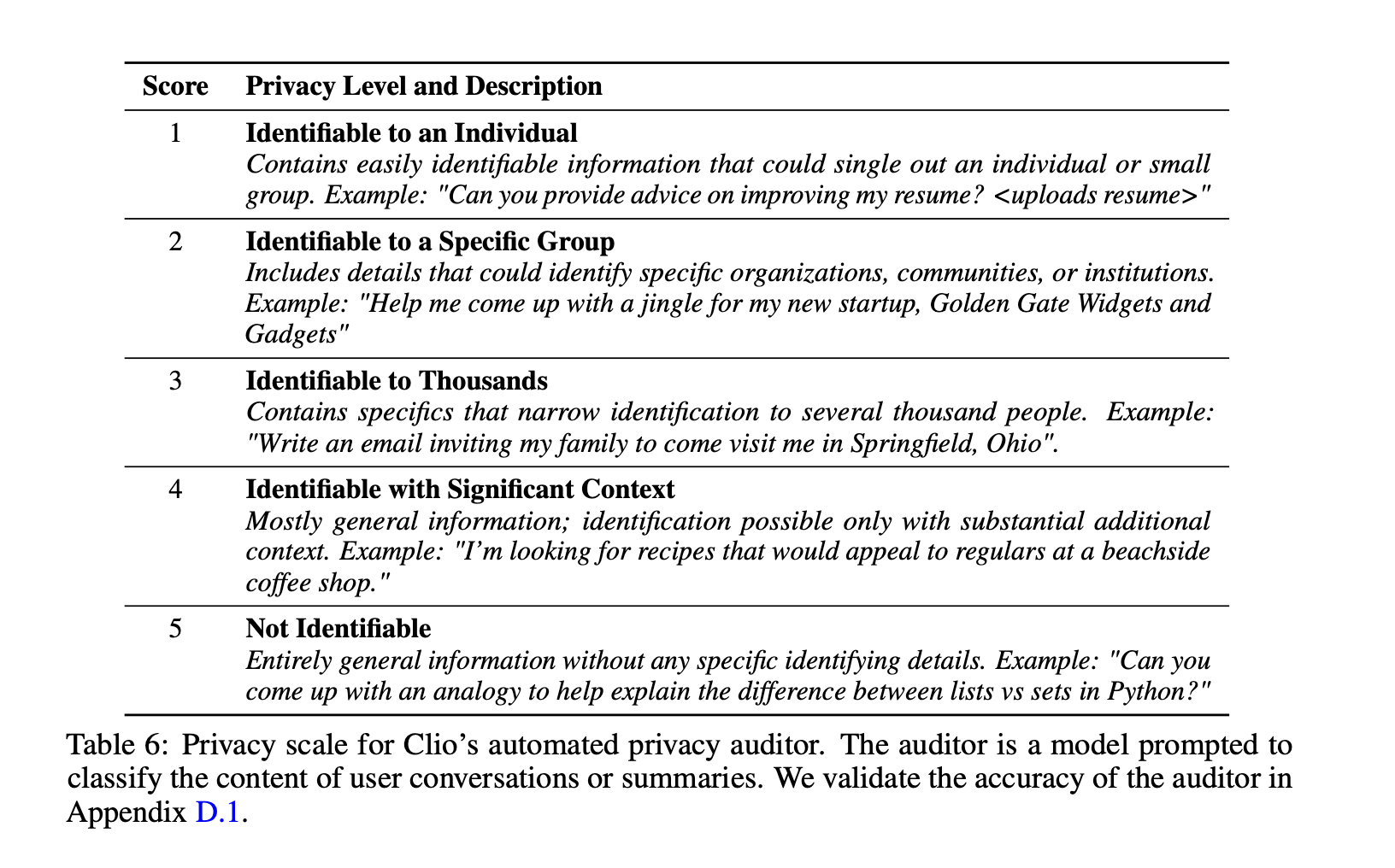
They bootstrapped this classifier by using a small dataset of initial user messages that they had manualy labelled as non PII and then synthetically generated more data by deliberately adding PII to the data. This allowed them to see how their haiku performed on this specifc task - showing that with the summarisation step, we were able to remove PII in 98.5% of the data.

Explainability
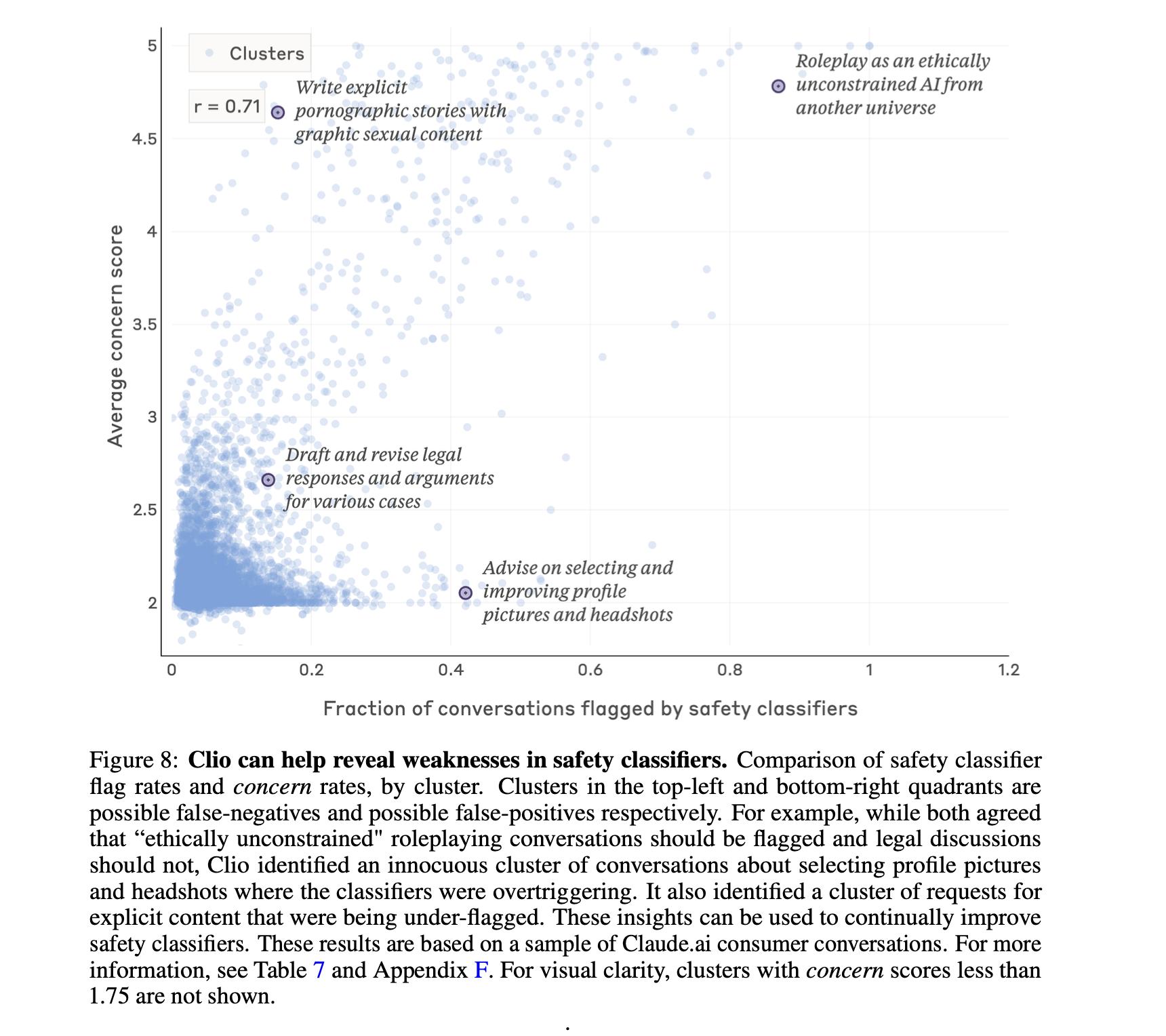
By using a language model to generate their clusters and descriptions and a language model for a classifier, Anthropic was able to generate a significantly larger amount of data on why specific clusters were generated or why a conversation was labelled as exposing PII.
This in turn helped to develop more fine grained classifiers for their PII classifier as well as tune their prompts for the language models as seen below.
Implementing CLIO
Now that we understand on a high level how CLIO works, let's implement a simplified version of it in Python. We'll be using gemini-1.5-flash since it's cheaper to use and I have higher rate-limits on it. I've put together a Github Repository with the code here where you can find the code for this article.
It also contains a FastHTML application that you can use to generate and visualise your own clusters.
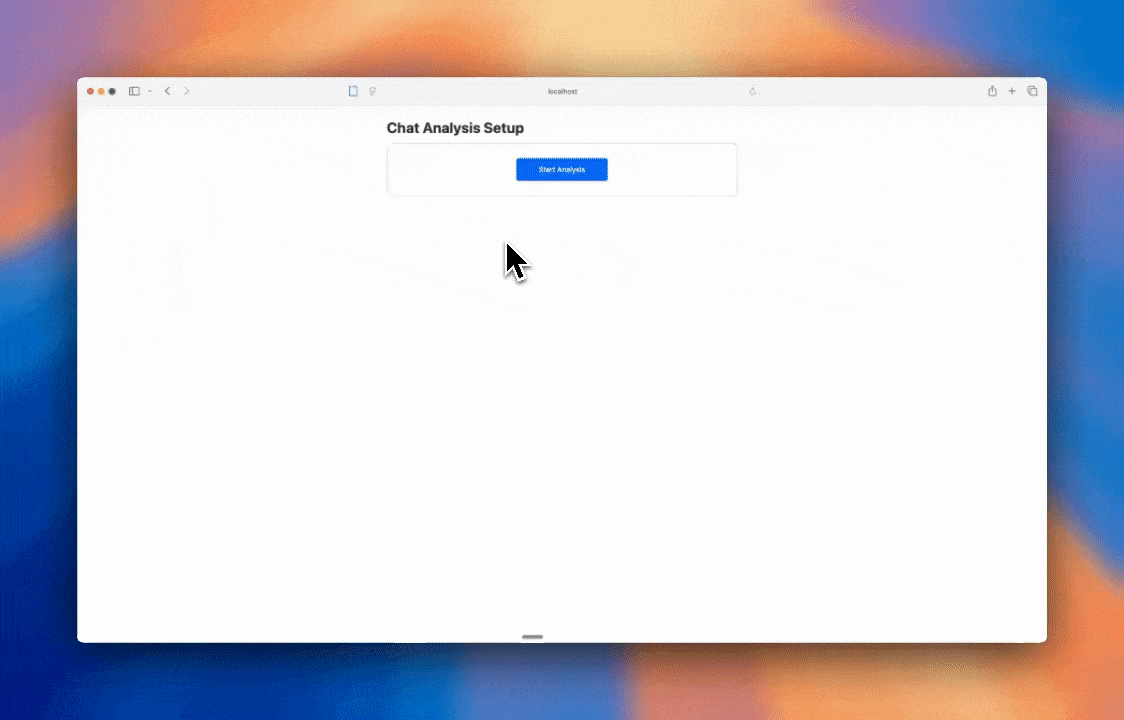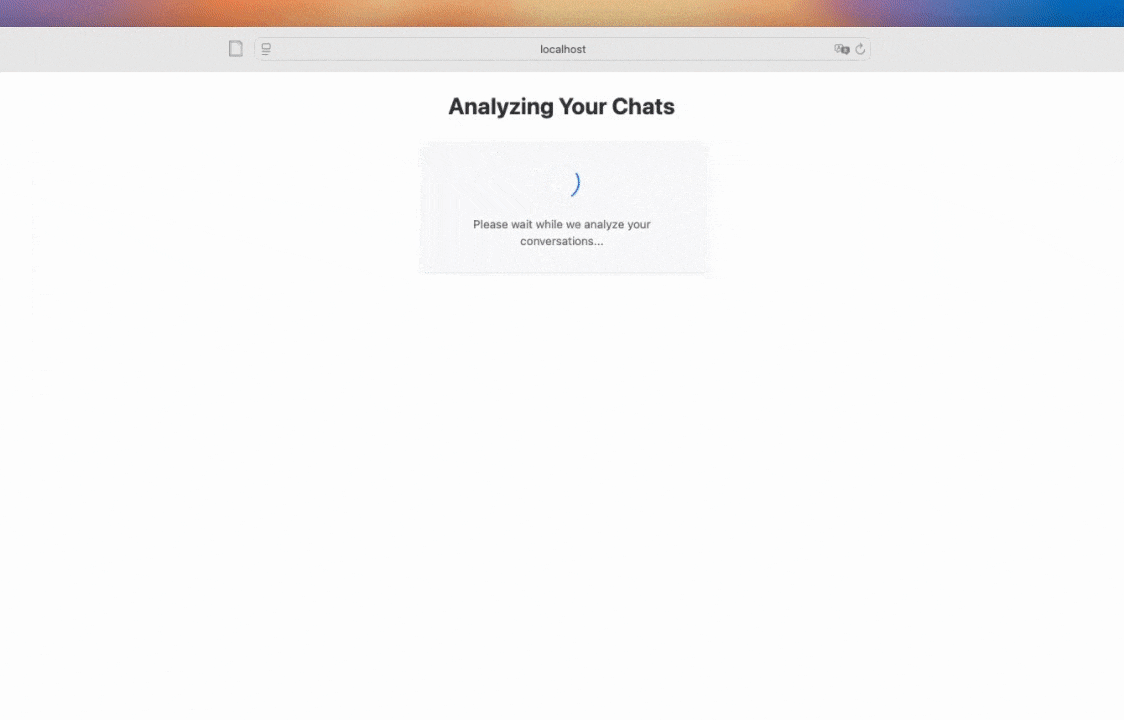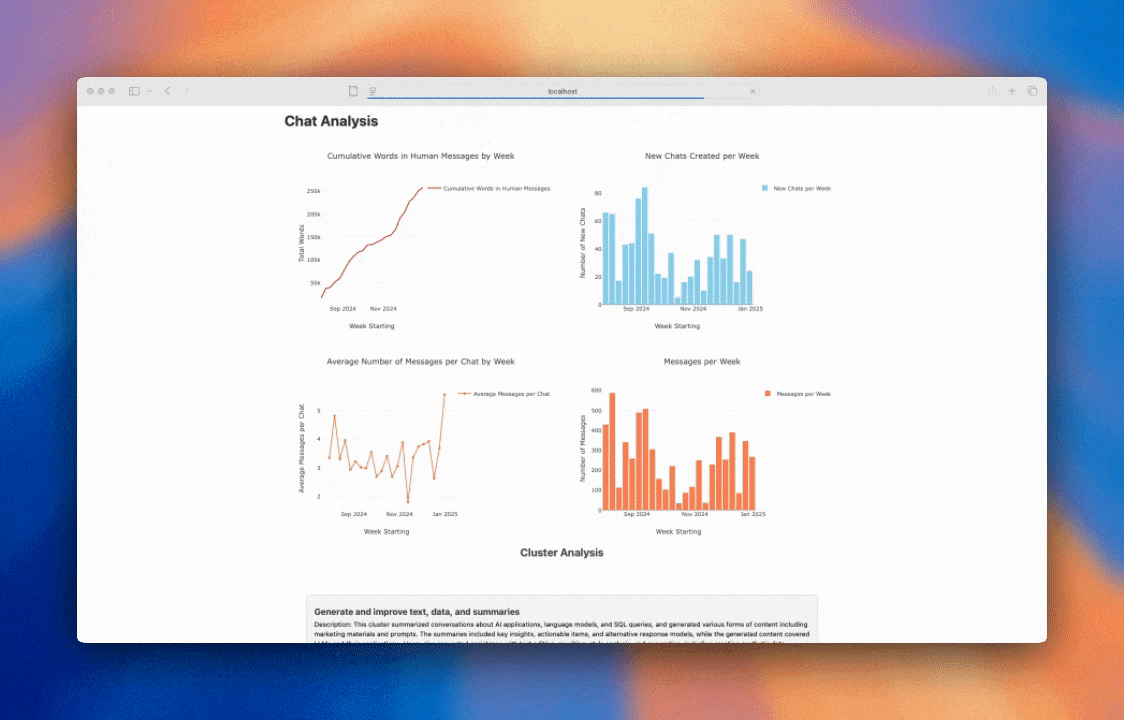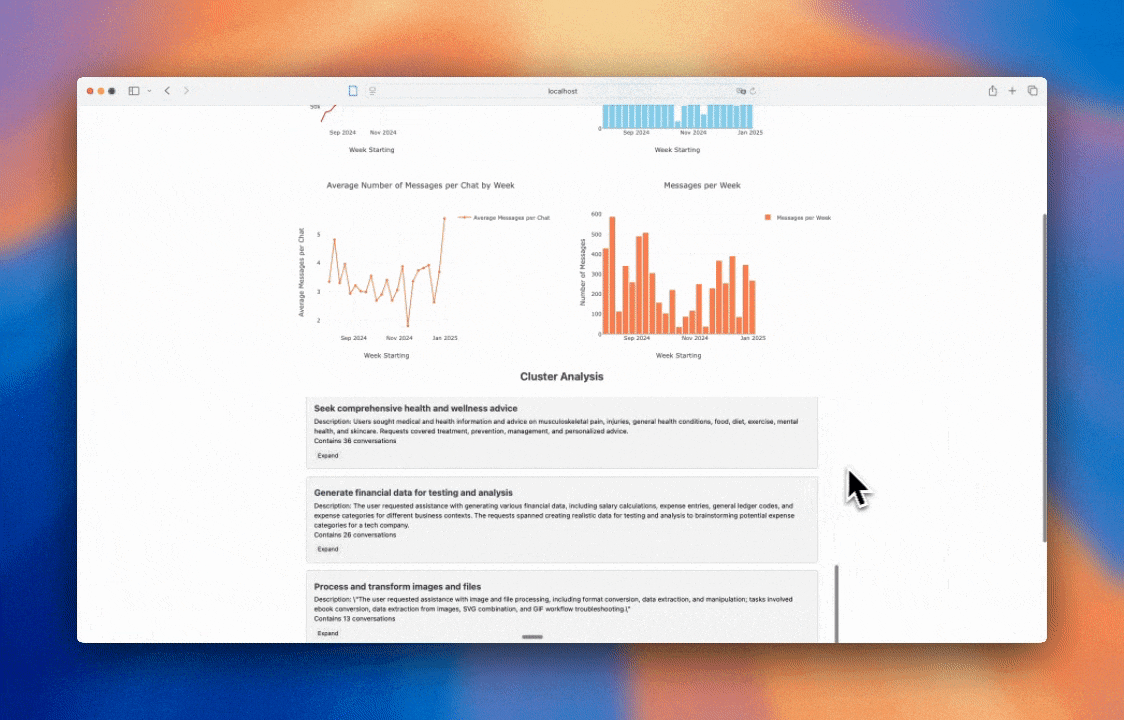
We'll do so in 3 steps.
- Summarisation : We'll first start by generating a condensed summary of each conversation using
gemini-1.5-flash. - Clustering : We'll then show how we can use a language model to cluster these summaries and create an explainable cluster
- Hierachal Clustering : Finally, we'll show how our recursive clustering approach works to generate a hierachal clustering of the data
Because our prompts will get a bit more complex, we'll use instructor to help us format our prompts nicely with jinja templating support and the ability to obtain structured outputs.
Summarisation
CLIO works by generating a condensed summary of each conversation. For each, we pass in the conversation and extract out two main components
| Component | Description | Examples |
|---|---|---|
| User Request | A description of what the user is asking for | - The user's overall request for the assistant is to help implementing a React component to display a paginated list of users from a database - The user's overall request for the assistant is to debug a memory leak in their Python data processing pipeline |
| Task Description | A description of the task generated by the language model | - The task is to help build a frontend component with React and implement database integration - The task is to debug performance issues and optimize memory usage in Python code |
We can do so with the function defined below
def summarise_conversation(client, conversation) -> dict:
"""
Given a user conversation, returns a summary of the user request and task description.
"""
resp = client.chat.completions.create(
messages=[
{
"role": "system",
"content": """Summarize the conversation by providing:
1. A user request starting with "The user's overall request for the assistant is to"
2. A task description starting with "The task is to"
Keep each to 1-2 sentences and max 20 words. Include relevant technical details like programming languages and frameworks.
Exclude any PII (names, locations, emails, companies, etc).
Example User Request:
- The user's overall request for the assistant is to help implementing a React component to display a paginated list of users from a database.
Example Task Description:
- The task is to help build a frontend component with React and implement database integration
Here is the conversation:
{% for message in messages %}
<message>{{message.role}}: {{message.content}}</message>
{% endfor %}
"""
}
],
context={"messages": conversation.messages},
response_model=ConversationSummary,
)
return {
"chat_id": conversation.chat_id,
"task_description": resp.task_description,
"user_request": resp.user_request,
"turns": len(conversation.messages),
}
Notice here how we're also extracting out the turns in this conversation here. Depending on your specific use-case, you may want to extract out other bits of information like the language, user_id, organisation etc so that you can implement deduplication or other forms of analysis.
This allows us to take a conversation and extract out the user request and task description. For instance, given the exchange below, we can extract out the user request and task description as follows Here's an example conversation:
| Role | Message |
|---|---|
| Human | what's the weather in Tokyo? |
| Assistant | The weather in Tokyo is currently 20 degrees Celsius with clear skies. |
| Human | Thanks, what should I wear out in the city today? I'm headed into Ginza for a quick shopping trip with Jake my best friend before i go into the OpenAI office |
| Assistant | It's a bit chilly, so I recommend wearing a light jacket and jeans. |
This would be processed into:
| Field | Content |
|---|---|
| User Request | The user's overall request for the assistant is to get weather and clothing recommendations |
| Task Description | The task is to provide weather information and suggest appropriate clothing based on conditions |
We can see that with the summarisation step, we've removed the PII ( The exact company he works at, the name of his friend etc) and we've also removed the location ( Tokyo, Ginza etc). Instead, we've extracted out the rough user request and task description that the user is trying to achieve - in this case get weather and clothing recommendations.
Clustering
Once we've obtained a few summaries, we can then just embed them and use a simple K-Means clustering algorithm to group them together.
I used the text-embedding-3-small model to embed the summaries and then used sklearn to perform the clustering.
def cluster_items(items: list[dict], items_per_cluster: int) -> list[dict]:
n_clusters = math.ceil(len(items) // items_per_cluster)
embeddings = [item["embedding"] for item in items]
X = np.array(embeddings)
kmeans = KMeans(n_clusters=n_clusters)
cluster_labels = kmeans.fit_predict(X)
group_to_clusters = {}
for i, item in enumerate(items):
item_copy = item.copy()
cluster_id = int(cluster_labels[i])
del item_copy["embedding"]
if cluster_id not in group_to_clusters:
group_to_clusters[cluster_id] = []
group_to_clusters[cluster_id].append(item_copy)
return group_to_clusters
Once we've done so, we obtain a list of conversation summaries that we can then use to generate a cluster. What's cool about CLIO's approach is that it uses positive and contrastive examples to generate this cluster.
async def generate_base_cluster(client, sem, user_requests: list[dict], negative_examples: list[dict]):
async with sem:
cluster = await client.chat.completions.create(
messages=[
{
"role": "system",
"content": """
Summarize related statements into a short description and name. Create a concise two-sentence summary
in past tense that captures the essence and distinguishes from other groups.
Generate a specific name under 10 words in imperative form (e.g. "Help debug Python code").
Be descriptive and distinguish from contrastive examples.
"""
},
{
"role": "user",
"content": """
Here are the relevant statements:
<positive_examples>
{% for item in user_requests %}
<positive_example>{{ item['user_request'] }} : {{ item['task_description'] }}</positive_example>
{% endfor %}
</positive_examples>
For context, here are statements from other groups:
<contrastive_examples>
{% for item in negative_examples %}
<contrastive_example>{{ item['user_request'] }} : {{ item['task_description'] }}</contrastive_example>
{% endfor %}
</contrastive_examples>
Analyze both sets of statements to create an accurate summary and name.
"""
}
],
response_model=ClusterSummary,
context={
"user_requests": user_requests,
"negative_examples": negative_examples
}
)
return Cluster(
name=cluster.name,
description=cluster.summary,
chat_ids=[item["chat_id"] for item in user_requests],
parent_id=None
)
For instance, given the following user chat summaries
| User Request | Task Description |
|---|---|
| The user's overall request for the assistant is to help build a React data table with sorting functionality | The task is to implement a reusable React component for displaying and sorting tabular data |
| The user's overall request for the assistant is to implement a paginated user list component in React | The task is to create a React component that handles pagination and displays user records |
| The user's overall request for the assistant is to create a React component for displaying filtered database records | The task is to develop a React component that can filter and display data from a database |
and the following contrastive examples
| User Request | Task Description |
|---|---|
| The user's overall request for the assistant is to debug a Python memory leak | The task is to identify and fix memory leaks in a Python application |
| The user's overall request for the assistant is to get restaurant recommendations in their area | The task is to provide personalized dining suggestions based on location and preferences |
| The user's overall request for the assistant is to analyze a CSV file using pandas | The task is to perform data analysis on a CSV dataset using the pandas library |
We could instead generate a cluster with the following name and description
| Name | Description |
|---|---|
| Help implement Frontend Components | The task is to help build reusable React components for displaying and manipulating tabular data, including features like sorting, pagination, and filtering. These components need to integrate with backend data sources and provide a smooth user experience for viewing and interacting with database records. |
This is a much more descriptive name and description that captures the essence of the user request and task description. At the same time it doesn't include any PII information.
Hierachal Clustering
CLIO implements Hierachal Clustering in 3 main steps
- First we generate new candidate clusters by using the existing clusters and their descriptions
- Then we label each of our original clusters with our new cluster ( creating a new cluster for each of our original clusters)
- We then repeat this process until we've reduced the number of clusters to a number that we want
This allows us to generate a hierachal clustering of the data.
Let's see this in action
Generating Candidate Clusters
Let's start by looking at a few examples of clusters here that I've added below.
Categorize and analyze business expenses
The user requested assistance with categorizing and analyzing business expenses, including generating expense categories, identifying overlapping categories, and improving pricing plans. This involved tasks such as creating comprehensive expense code lists, brainstorming department expense usage, and understanding financial reporting concepts like deferred revenue and customer lifetime value (CLV).
Generate realistic, ambiguous business transactions and general ledger codes
The user requested assistance generating general ledger codes and ambiguous business transactions, aiming for realistic yet ambiguous classifications spanning multiple categories. This involved tasks such as generating mock transactions, improving transaction naming and classification, and creating challenging examples for annotation and improved accounting software functionality.
Improve code using Pydantic and Instructor
The user requested assistance with various tasks involving Pydantic and Instructor, including code improvement, debugging, and model building. These tasks focused on refining code clarity, enhancing functionality, and addressing specific validation or structural issues within the context of these tools.
Explain concurrent programming concepts in Rust
The user requested assistance with understanding various aspects of concurrent programming in Rust, including memory ordering, threads, atomic operations, reader-writer locks, interior mutability, and crate management. These requests focused on improving the user's understanding of concurrent programming techniques within the Rust programming language.
With the following function, we can then generate a list of candidate cluster names. In the case below, we have 4 clusters, and we want to generate at msot 3 candidate clusters.
This might result in the following candidate cluster names
- Analyze and categorize business financial data
- Improve and debug code and application
- Explain Rust and Python code
async def generate_candidate_cluster_names(
client: instructor.Instructor, sem: Semaphore, clusters: list[Cluster]
) -> list[str]:
resp = await client.chat.completions.create(
messages=[
{
"role": "system",
"content": """
Create higher-level cluster names based on the provided clusters and descriptions. Generate broader categories that could include multiple clusters while remaining specific and meaningful.
Review these clusters:
<cluster_list>
{% for cluster in clusters %}
<cluster>{{ cluster.name }}: {{ cluster.description }}</cluster>
{% endfor %}
</cluster_list>
Create at most {{ desired_number }} higher-level cluster names. The names should:
- Represent broader themes found in multiple clusters
- Be specific enough to be meaningful
- Be distinct from each other
- Use clear, descriptive language
- Accurately describe sensitive or harmful topics when present
Generate fewer than {{ desired_number }} names if that better captures the clusters.
""",
}
],
response_model=CandidateClusters,
context={
"clusters": clusters,
"desired_number": math.ceil(
(len(clusters) * 3) // 4
), # This ensure we get at least 3/4 of the clusters ( so we have a 25% reduction or more at each stage)
},
)
return resp.candidate_cluster_names
Labeling Clusters
Now that we have a list of candidate cluster names, we can then label each of our original clusters with our new cluster. It's important here that we need to shuffle the cluster names that we present to the language model so that we don't bias the language model.
async def rename_higher_level_cluster(
client: instructor.AsyncInstructor,
sem: Semaphore,
clusters: dict,
) -> dict:
async with sem:
resp = await client.chat.completions.create(
messages=[
{
"role": "system",
"content": """
Create a concise name and description for these related clusters.
The name should be:
- Max 10 words
- An imperative sentence
- Specific and descriptive
- Accurately describe sensitive topics
The description should be:
- Two sentences in past tense
- Clear and precise
- Specific to this cluster
Below are the related cluster names:
<clusters>
{% for cluster in clusters %}
<cluster>{{ cluster.name }}: {{ cluster.description }}</cluster>
{% endfor %}
</clusters>
""",
}
],
context={"clusters": clusters},
response_model=ConsolidatedCluster,
)
return {
"new_cluster": Cluster(
name=resp.cluster_name,
description=resp.cluster_description,
chat_ids=[chat_id for cluster in clusters for chat_id in cluster.chat_ids],
parent_id=None,
),
"original_clusters": clusters,
}
Once we've done so, we can then repeat this process for all of the clusters that we have. With this, we've generated a list of clusters that are smaller than the lst of clusters we started with. We've also labelled each of our original clusters with our new cluster.
In our case, this might result in the following clusters and their labels
| Original Cluster Name | Consolidated Cluster Label |
|---|---|
| Categorize and analyze business expenses | Analyse and categorize business financial data |
| Generate realistic, ambiguous business transactions and general ledger codes | Analyse and categorize business financial data |
| Improve code using Pydantic and Instructor | Improve and debug code and application |
| Explain concurrent programming concepts in Rust | Improve and debug code and application |
Once we've done so, we've now reduced our original 4 clusters to 2 clusters. But notice here that we only have a label. That's where a third step comes in.
Generating New Clusters
Now that we've succesfully clustered our clusters, we have a list of base clusters with a name and a description. We can then use this to generate a new cluster with a more descriptive name and description.
async def rename_higher_level_cluster(
client: instructor.AsyncInstructor,
sem: Semaphore,
clusters: dict,
) -> dict:
async with sem:
resp = await client.chat.completions.create(
messages=[
{
"role": "system",
"content": """
You are tasked with summarizing a group of related cluster names into a short, precise, and accurate overall description and name. Your goal is to create a concise summary that captures the essence of these clusters
The cluster name should be at most ten words long (perhaps less) and be specific but also reflective of most of the clusters that comprise them. The cluster name should be a sentence in the imperative that captures the user’s request. For example, ‘Brainstorm ideas for a birthday party’ or ‘Help me find a new job are good examples.
Do not shy away from describing socially harmful or sensitive topics. For instance, "Write fantasy sexual roleplay with octopi and monsters", "Generate blog spam for gambling websites", or "Assist with high school math homework" would be better than "Write erotic content" or "Help with homework". Be as descriptive as possible and assume neither good nor bad faith. Do not hesitate to identify and describe socially harmful or sensitive topics specifically; specificity is necessary for monitoring.
The cluster description should be a clear, precise, two-sentence description in the past tense. This description should be specific to this cluster.
Below are the related cluster names
<clusters>
{% for cluster in clusters %}
<cluster>{{ cluster.name }}: {{ cluster.description }}</cluster>
{% endfor %}
</clusters>
Ensure your summary and name accurately represent the clusters and are specific to the clusters.
""",
}
],
context={"clusters": clusters},
response_model=ConsolidatedCluster,
)
return {
"new_cluster": Cluster(
name=resp.cluster_name,
description=resp.cluster_description,
chat_ids=[chat_id for cluster in clusters for chat_id in cluster.chat_ids],
parent_id=None,
),
"original_clusters": clusters,
}
This in turn gives us a new cluster with a name and description. We can then repeat this process until we've reduced the number of clusters to a number that we want. In our case, this gives us the following clusters
Help analyze and categorize business financial data
The user requested assistance with analyzing and categorizing financial data, including expense tracking, transaction classification, and financial metrics analysis. The tasks involved creating expense categories, generating sample transactions, and building tools for financial reporting and analysis.
Debug and optimize code across programming languages
The user requested help with debugging, optimizing and improving code quality across multiple programming languages and frameworks. The tasks focused on performance optimization, concurrent programming patterns, and developing robust database-driven applications.
With this, we've now generated a hierachal clustering of the data! That's basically the high level overview of what CLIO does and how we can use instructor to implement it.
Limitations
In this article, we've walked through how we can implement CLIO in python. However, there are a few limitations that we need to be aware of.
-
Unvalidated Clustering Parameters : Currently the K-Means cluster counts are chosen arbitrarily by taking the total number of conversations and dividing it by the target cluster size. Since the choice of
kdirectly impacts how well clusters capture distinct conversational patterns, we need to be more careful here. -
Basic PII Removal : In Anthropic's case, they have a specific PII classifier that they use to remove PII. However, this is a very basic classifier that only looks at the user request and task description. A production system should invest time into building out a more sophisticated PII classifier that can be used to remove PII from the data.
-
More Concrete Evaluations: Ultimately, if you're looking to implement CLIO, you'll want to have a more concrete evaluation framework in place. This will allow you to measure the quality of your clusters and ensure that you're getting the most out of your data. Anthropic does this by using a combination of manual validation and synthetic data generation but you should also validate manually that the clusters are meaningful and that the PII is removed. Our implementation of CLIO revealed four main technical limitations that affect its practical usage:
Conclusion
CLIO offers a promising approach to understanding user conversations at scale while preserving privacy through its combination of summarization, clustering, and hierarchical organization. While our implementation demonstrates the core concepts, a production system would benefit greatly from domain expert involvement to validate cluster quality and ensure the insights are actionable for specific business needs.
Ultimately, it's important to reiterate that clustering algorithms are just ways for you to understand your data. They're not absolute truths and you should always be careful to validate your results. The goal isn't perfect clustering but rather gaining meaningful, privacy-preserving insights that can drive product improvements while maintaining user trust.